|
|
| . |
SynqNet Fault Recovery
On a SynqNet network, it is important that the communication between the nodes and the controller is not compromised by missing packets. If a significant number of packets are being lost, it is important that the network is able to reroute the flow of packets so that a sufficient level of data integrity can be maintained. One of the key safety features on a Ring topology is that when packets are being lost during either an upstream or downstream flow, the idle link can be used as an alternative path for sending and receiving packets. The SynqNet Fault Recovery feature allows the network to use the idle link for correcting faulty communication without having to perform an emergency shutdown of the network. It essentially gives the system a buffer of tolerance that allows the network to continue to operate, as long as the Fail Limit has not been reached. Since the presence of an idle link is required for SynqNet Fault Recovery, this feature is NOT available on networks with String topologies. WARNING! The example below explains what happens on a SynqNet network when a node enters the Fault Recovery mode after its Packet Error Rate Counter has reached its Fault Limit threshold. The table below shows the Packet Error Rate Counters at the controller and nodes during each controller period. For simplicity, the example below assumes that the Packet Error Counter and Packet Error Rate Counter are identical. The default, Downstream Fault Limit is when when
the Packet Error Rate Counter = 6 For information about packet errors, please see the Packet Error Counters section.
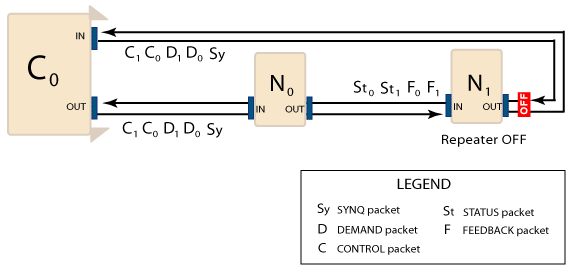
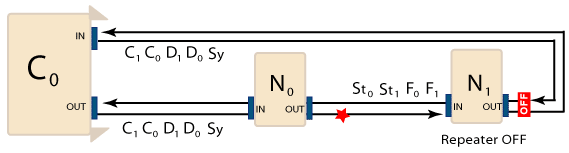
In the example above, the SynqNet network is operating normally and all packets are being received. Since no packets are being lost, the network behaves just like a network with a String topology. Although packets are sent from both ports of the controller in a Ring topology, the Repeater on the last node blocks the packets from being received by the node when its Repeater is OFF. For example, although packets are being sent to the OUT port of N1, it is only receiving packets from its IN port. Therefore, the Repeater remains OFF at the last node in the network until the Fault Limit has been reached for a node. The next two controller periods show a problem with the downstream flow of packets from N0 to N1. Packets are not being received by N1.
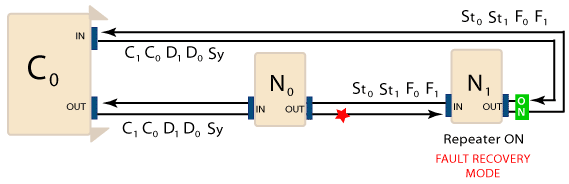
Once the Fault Limit has been reached (n = 6), N1 enters the Fault Recovery mode. The repeater on N1 is turned ON and N1 starts to receive its packets from its OUT port.
In the next controller period (P + 3), zero packets are lost and the Packet Error Rate Counter for N1 remains at 6. N1 remains in Fault Recovery Mode until the system is shut down and reset.
MPI Software PerspectiveNetwork fault recovery is only supported with ring topologies. If any single network connection fails, the network traffic will be automatically re-routed around the faulty connection via the idle link. The controller can be configured to notify the host application when the fault recovery occurs. WARNING! Events Fault Location (Idle Cable) If the faulted cable is replaced or you want to test the idle cable, use mpiSynqNetIdleCableStatus(...). This will send a special test packet across the idle cable to verify the upstream and downstream data path is operational. The status will report: MPISynqNetCableStatusGOOD - communication test passed. MPISynqNetCableStatusBAD_UPSTREAM - upstream communication test failed. MPISynqNetCableStatusBAD_DOWNSTREAM - downstream communication test failed. MPISynqNetCableStatusBAD - communication test failed. Recovery Mode MPISynqNetRecoveryModeDISABLED (default for string topology) - Network does not attempt to redirect network traffic around a fault. MPISynqNetRecoveryModeSINGLE_SHOT - Network will redirect network traffic around a fault one time. A second fault will cause all nodes downstream from the fault to fail. MPISynqNetRecoveryModeAUTO_ARM (default for ring topology) - Network will redirect network traffic around a fault each time a fault occurs. After the network traffic redirection, the controller will wait for the node(s) upstream and downstream packet error rate counters to decrement to zero until the recovery is re-armed. Then, the network will be able to respond to another fault. Most applications will want to use the default recovery mode. If a ring topology network has marginal operational characteristics (large number of packet errors) it might be useful to set the mode to SINGLE_SHOT or DISABLED during troubleshooting. It is easier to determine the network behavior when it is not trying to recover from faults. Examples Single cable break causing a network fault.
Expected BehaviorA node will almost always receive ALL of its packets. An acceptable Packet Error Rate is roughly 0-1 errors per day. However, if you are experiencing one or more errors per hour, you should definitely check the data integrity of your system. A high error rate is almost always caused by a faulty cable/connector or a bad connection. Troubleshooting
|
|||||||||||||||||||||||||||||||||||||||||
| | | Copyright © 2001-2021 Motion Engineering |